728x90
반응형
db검색의 한계점
"흰색모자" 검색 시,
- select title from product where title like '%흰색모자%'
- '흰색모자' 와 완벽하게 일치해야 효율적인 사용이 가능하다.
- 쿼리가 복잡해짐.
- 대량의 데이터 처리시 성능 한계 존재.
Elastic search: 분산형 검색 엔진, 대용량 데이터를 실시간으로 처리하고 분석하는 능력이 뛰어남.
다양한 형태의 데이터를 색인 가능, 복잡한 검색 쿼리에 대해서도 빠르고 정확한 결과를 제공.
왜 사용?
- 루씬 기반의 검색 엔진. 복잡한 데이터 셋에서 정보를 신속하고 정확하게 검색
- 다양한 데이터 관리 지원
- 유연한 색인화(json 형식 색인화) 및 api 제공.
- 분산 시스템 및 효율적 데이터 관리.
- Kibana 와의 연계 (시각화 도구)
Elastic Stack?
Elastic search 검색, Kibana 분석 시각화, LogStash 데이터 변경, Beats 수집
을 제공하는 소프트웨어스택.
- 지원 기능
- 자동 완성, 필터, 랭킹 기능을 통한 검색 결과 제공
- 강력한 보안 기능
- APM 도구로서의 역할
- 풍부한 매트릭스 시각화
- 서비스 모니터링 기능
- 구성 요소
- Elastci search :
- 빠르게 저장된 문서를 검색, 분석할 수 있는 검색 엔진
- 데이터를 실시간으로 색인
- 다양한 쿼리와 필터를 통한 검색 결과 반환
- json 기반 데이터 유연성
- 전문 검색 기능 full text search
- 세밀한 검색 및 필터링
- 다양한 검색 쿼리 유형 지원
- 높은 확장성 및 안정성
- Kibana
- 엘라스틱서치에 저장된 데이터 시각화
- 데이터를 통한 그래프, 차트, 지도 등 대시보드 구성
- 검색 쿼리를 작성하고 검색해 볼 수 있는 화면 제공
- 실시간 모니터링 지원
- Beats
- 경량 데이터 수집기. 메모리와 cpu 사용이 적음
- 다양한 모듈로 구성, 특정 데이터 소스에 따라 데이터를 수집하는 역할
- 다양한 데이터 수집 플러그인
- 데이터의 실시간 처리와 전송
- 데이터 전송의 보안 기능
- 중앙화된 데이터 관리 지원
- 엑셀러 레이트 Elastic APM
- 애플리케이션 성능 모니터링 기능
- 애플리케이션 내부 성능 수집 및 모니터링 ( 트랜잭션, 지연분석)
- 다양한 애플리케이션 프레임 워크와 언어 지원
- Elastci search :
- 특징
- 중앙 집중화된 데이터 관리
- 실시간성 플랫폼
- 즉가적인 데이터 대응
- 다양한 클라이언트 라이브러리와 API
- 사용자 운영 편의성 및 유지보수 효율성
728x90
RDB(관계형 DB)와 Elastic search 용어 비교
| RDB | Elastic search | |
| 테이블 | 인덱스 | 데이터 저장하고 관리 |
| 한 행 | 문서 (json 형식으로 저장) | |
| 컬럼 | 필드(동적으로 추가, 수정 가능. 데이터 구조 변화에 유연하게 대응) | |
| 물리파티션 | 샤드 | |
| 스키 | 매핑 |
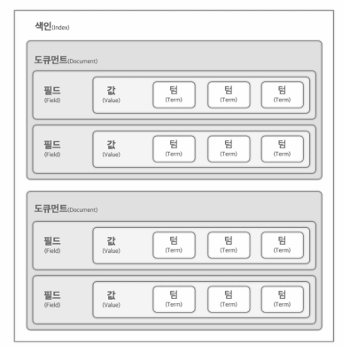
인덱스의 구성
- 인덱스: 데이터 저장 및 검색을 위한 데이터 구조. 여러 개의 도큐먼트 포함 가능. 각 고유한 이름이 있어 해당 이름을 사용해 데이터 조회, 관리.
- Document 문서: 인덱스 내 json 형식의 데이터 기본 단위. 데이터를 표현하는 단위.하나의 문서는 하나의 엔티티를 나타낸다. 필드의 집합으로 구성된다.
- 필드: 각 문서는 데이터 속성이나 특성을 나타내는 필드로 구성. 각 문서를 여러 개의 필드를 가질 수 있다.필드는 문서의 속성을 나타낸다. 예를 들어 사람 문서의 경우 name, email, age 같은 필드가 있을 수 있다. 실제의 데이터.
- 텀 term : 필드 내 실제 데이터 단위. elastic search 에 색인되고 검색 할 단어 저장
노드의 개념
- 노드의 정의: elastic search 클러스터를 구성하는 개별 서버 인스턴스. 실제 데이터를 저장하고, 쿼리를 처리하는 개별 처리 서버 혹은 시스템.
- 역할과 기능: 데이터 저장, 검색, 분석, 쿼리 처리 등 포함한 다양한 작업 처리
- 클러스터 연결: 각 노드는 고유한 이름과 식별 정보(IP, port)를 가지고 클러스터 내에서 협력, 클러스터 관리. 다른 노트와 통신하여 데이터를 조정하거나 균등하게 분배 가능.
- 노드 유형: 마스터 노드, 데이터 노드, 코디네이팅 노드 등 각각의 특정 역할 수행
- 노드 구성의 중요성: 클러스터의 성능과 안정성에 영향을 미침.
- 각 노드는 클러스터의 일부. 데이터를 저장하고, 클러스터 내에서 작업을 분담한다.
마스터 노트
- elastic search 클러스터의 핵심 관리자, 클러스터의 안정적인 운영을 책임진다
- 클러스터 내 인덱스 생성 및 삭제, 노드 관리, 샤드 분배 등 중요한 결정을 내린다.
- 클러스터의 연속적인 서비스 제공을 위해 적어도 한 개 이상의 마스터 노드 필요 (실제 운영 환경에서는 3개 이상의 마스터 노드)
- 클러스터 상태를 모니터링 하며, 필요한 경우 마스터 노드 역할을 수행할 수 있는 노드로의 전환을 관리.
데이터 노드
- elastic search 클러스터에서 데이터를 실제 저장하고 관리하는 역할
- 색인, 검색, 집계 담당. CPI, I/O , 메모리와 같은 하드웨어 리소스를 많이 소모
- 클러스터 안정성을 위해 데이터 노드는 적정한 수를 유지하고 장애 발생 시를 대비해 적절한 샤드 운영을 해야함.
- 데이터 노드 종류에는 여러 가지가 있으며 데이터의 특성과 접근 패턴에 맞게 조정
- 데이터 노드 구성은 성능 최적화 클러스터의 안정성, 비용적인 측면에서 직접적인 영향을 끼침.
- 데이터 노드의 종류
- data_content: 지속적으로 유지되어야 하는 데이터 저장, 주로 읽기 작업이 많은 검색 집계 쿼리에 사용
- data_hot: 최신 데이터를 빠르게 읽고 쓰는데 필요, 고성능 SSD 같은 저장 장치를 사용하여 최근 데이터 엑세스
- data_warm: 쿼리 빈도가 낮은 데이터를 보관. 비용 효율적인 HDD 를사용, 몇 주 전 데이터를 저장
- data_cold: 빠르게 검색 할 필요 없는 오래된 데이터 보관하며, 필요에 따라 데이터를이동시켜 저장 공간을 효율적으로 사용.
- data_frozen: 거의 사용되지 않거나 아카이브 목적의 데이터를 저장, 데이터 보전이 주된 목적일 때 사용.
- 데이터 노드의 종류
인제스트 노드 Ingest
- 데이터 수집, 가공 및 색인 전달 과정을 관리하는 노드
- 데이터를 전처리, 다양한 소스의 데이터를 효과적으로 처리. 필터링, 파싱, 변환 등 데이터를 최적화 형식으로 가공
- 로그, 센서 데이터, 웹크롤링 결과 등 다양한 데이터 유형을 처리할 수 있으며 가공된 데이터를 데이터 노드에 색인해 저장
- 데이터 처리 과정에서 리소스 사용이 높기 때문에, 인제스트 노드와 데이터 노드들을 분리해 운영하는 것이 좋음
- 인제스트 노드는 데이터 노드와 함께 구성되어 데이터 처리 및 색인 프로세스를 효율적으로 수행
클라이언트 노드
- 클러스터에 대한 요청을 받아 마스터 노드나 데이터 노드로 전달하는 역할을 한다.
- 쿼리 라우팅, 요청 처리, 러드 밸런싱을 담당한다.
코디네이팅 노드
- 클러스터의 요청을 라우팅하고, 상태를 관리하는 역할로 대규모 클러스에서는 별도로 분리해 운
클러스터
- 노드들의 집합, 노드들이 협력하여 데이터 저장, 검색 및 분석 작업 수행
- 클러스터는 여러 개의 노드가 모여 데이터를 분산 저장하고, 쿼리 작업을 분담하여 처리하는 환경을 제공한다.
- 각 노드는 고유한 이름, IP,를 통해 식별하며 클러스터에 가입하여 클러스터의 전반적인 상태를 관리, 데이터 관련 작업 처리
- 다양한 룰을 통해 각 노드에 특정 기능과 권한을 할당
- 데이터의 안정성과 지속적인 가용성을 보장하기 위해 가용영역에 걸쳐 노드를 분산 배치
- 대용량 데이터를 효율적으로 처리 가능하며, 필요에 따른 확장 용이
주요 기능
- 데이터 분산. 클러스터 내 여러 노드들은 데이터를 분산 저장. 이를 통해 고가용성과 확장성 확보
- 노드의 추가, 제거를 통한 시스템의 성능, 용량 조절
- 레플리카를 활용한 고가용성. 데이터가 손실되지 않게 여러 개의 복사본을 저장한다.
- 분산 쿼리 처리. 여러 노드들이 쿼리 작업을 분산 처리해 빠른 응답시간과 높은 성능 제공.
특징
- 고유한 이름
- 자동 리밸런싱. 샤드의 분배 빛 리밸런싱을 자동으로 처리. 클러스터에 새 노드가 추가되면, 기존 데이터를 새 노드에 자동으로 분배해 부하를 분산.
728x90
'기타' 카테고리의 다른 글
| linux - 명령어 실행 시 조회 순서, 명령어에 경로가 포함된 경우 실행 차 (0) | 2025.02.23 |
|---|---|
| linux 리눅스 권한, 명령어 (0) | 2025.02.19 |
| Redis 를 어디에 쓸까 (0) | 2025.01.10 |
| Redis란 (0) | 2025.01.08 |
| 대규모 서비스란 (0) | 2025.01.05 |